


































训练LLMs的过程就像写教科书
大模型都是通过数据进行训练的,对不懂的人来说,以为大模型的训练过程很神秘。其实不然,作者的观点是:其实就和写教科书一样,有背景、例题和练习题。这篇文章,我们就来学习一下。 看到推上Karpathy的比喻真的有趣且非常贴切。他把大语言模型(LLMs)的训练过程比作学生学习的过程,而训练数据就像一本教科书。 为了让模型更像有智慧的学生,我们需要给它提供三种不同类型的信息,分别对应教科书中的不同部分:背景信息、带解答的例题、以及练习题。下面我们用简单易懂的方式逐步拆解这个观点。 souce:https://x.com/karpathy/status/1885026028428681698 一】背景信息/讲解性内容(Background information / Exposition) 是什么? 这是教科书的核心部分,主要以解释概念、理论和背景知识为主。例如,数学教科书会先解释什么是“微积分”,它的定义、用途,以及相关公式。这部分的目的是让学生了解基础知识,并建立对主题的总体理解。 对应LLM的什么? 这是模型的【预训练阶段(Pretraining)】。在这个阶段,模型会读取大量的互联网数据(比如维基百科、新闻文章、书籍等),以此积累“背景知识”。就像我们学生时代在学习新学科时先看书了解基础内容一样,模型通过预训练掌握了自然语言的广泛知识。 为什么重要? 没有背景知识,就无法理解更复杂的内容。例如,如果学生从来没听说过“微积分”,即使给他再多的例题,他的学习也会事倍功半。同样,对于LLMs来说,预训练阶段的背景信息是理解和生成语言的基础。 二、带解答的例解(Worked Problems with Solutions) 是什么? 这是教科书中带有详细解答的例题。比如,教科书会先展示一个数学问题,然后一步步讲解如何解答。这些例题是专家的示范,告诉学生正确的思路和方法。 对应LLM的什么? 这是模型的【监督微调(Supervised Fine-tuning)】阶段。在这一阶段,专家提供“参考答案”,并教会模型如何在特定情境下生成理想的回答。例如,给模型一个问题:“如何写一封礼貌的商业邮件?” 然后训练数据里会有一个高质量、经过精心编写的参考答案。 为什么重要? 有了背景知识,学生依然需要看到“如何实际运用这些知识”的示范。通过观察专家的解题过程,学生可以模仿并内化这些思路。同样,LLMs通过监督微调学习人类语言的优雅表达和逻辑推理。 三、练习题(Practice Problems) 是什么? 这是最后一章参考答案写着「略」的练习题,通常只有问题和最终答案。例如,“求以下函数的导数”,后面只提供答案“f'(x) = 2x”。学生需要通过自己的尝试,用学到的方法解答这些问题。 对应LLM的什么? 这是模型的【强化学习(Reinforcement Learning)】阶段。在这个阶段,模型不再依赖人类直接提供的“标准解答”,而是通过反复尝试生成答案,并根据反馈(奖励或惩罚)调整它的行为。比如,在RLHF(通过人类反馈的强化学习)中,模型生成答案后,反馈系统会告诉它回答得好不好,模型通过这种反馈机制不断改进。 为什么重要? 学生只有通过练习,才能真正掌握知识,发现自己的错误并改进。同样,模型也需要通过试错来优化生成的答案质量。如果只给示范而没有练习,学生和模型都会停留在被动学习的阶段,无法主动解决问题。 四、为什么第3点(练习题)是新兴的前沿? Karpathy指出,我们已经在第1点(预训练)和第2点(微调)上投入了大量精力,但第3点(强化学习)还处于初步发展阶段,被认为是LLMs训练的下一个重要方向。 对于学生来说,练习题通常是最耗时但也是最有效的学习方式。没有足够的练习,学生可能会觉得自己懂了,但实际上并没有真正掌握。 对于LLMs来说,强化学习可以让模型在复杂或开放性任务上进一步提升能力,而不仅仅是机械地模仿人类的回答。 五、总结:如何给LLMs“写教科书”? Karpathy的核心观点是:训练LLMs的过程就像写教科书,我们需要同时包含三种数据: 背景知识(预训练):让模型了解世界的基本规则和概念。 示范解题(监督微调):教模型如何生成高质量的答案。 练习题(强化学习):通过试错让模型学会主动解决问题。(接下来的重要方向) 这种分层学习方法不仅对学生有效,对LLMs也同样适用。通过这种“教育方式”,我们可以培养出更智能、更灵活的模型,真正像一个优秀的学生一样,不仅能够理解知识,还能运用知识解决实际问题。 本文由 @Timjune 原创发布于人人都是产品经理。未经许可,禁止转载。 题图来自 Unsplash,基于 CC0 协议。 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。

大模型都是通过数据进行训练的,对不懂的人来说,以为大模型的训练过程很神秘。其实不然,作者的观点是:其实就和写教科书一样,有背景、例题和练习题。这篇文章,我们就来学习一下。

看到推上Karpathy的比喻真的有趣且非常贴切。他把大语言模型(LLMs)的训练过程比作学生学习的过程,而训练数据就像一本教科书。
为了让模型更像有智慧的学生,我们需要给它提供三种不同类型的信息,分别对应教科书中的不同部分:背景信息、带解答的例题、以及练习题。下面我们用简单易懂的方式逐步拆解这个观点。
souce:https://x.com/karpathy/status/1885026028428681698
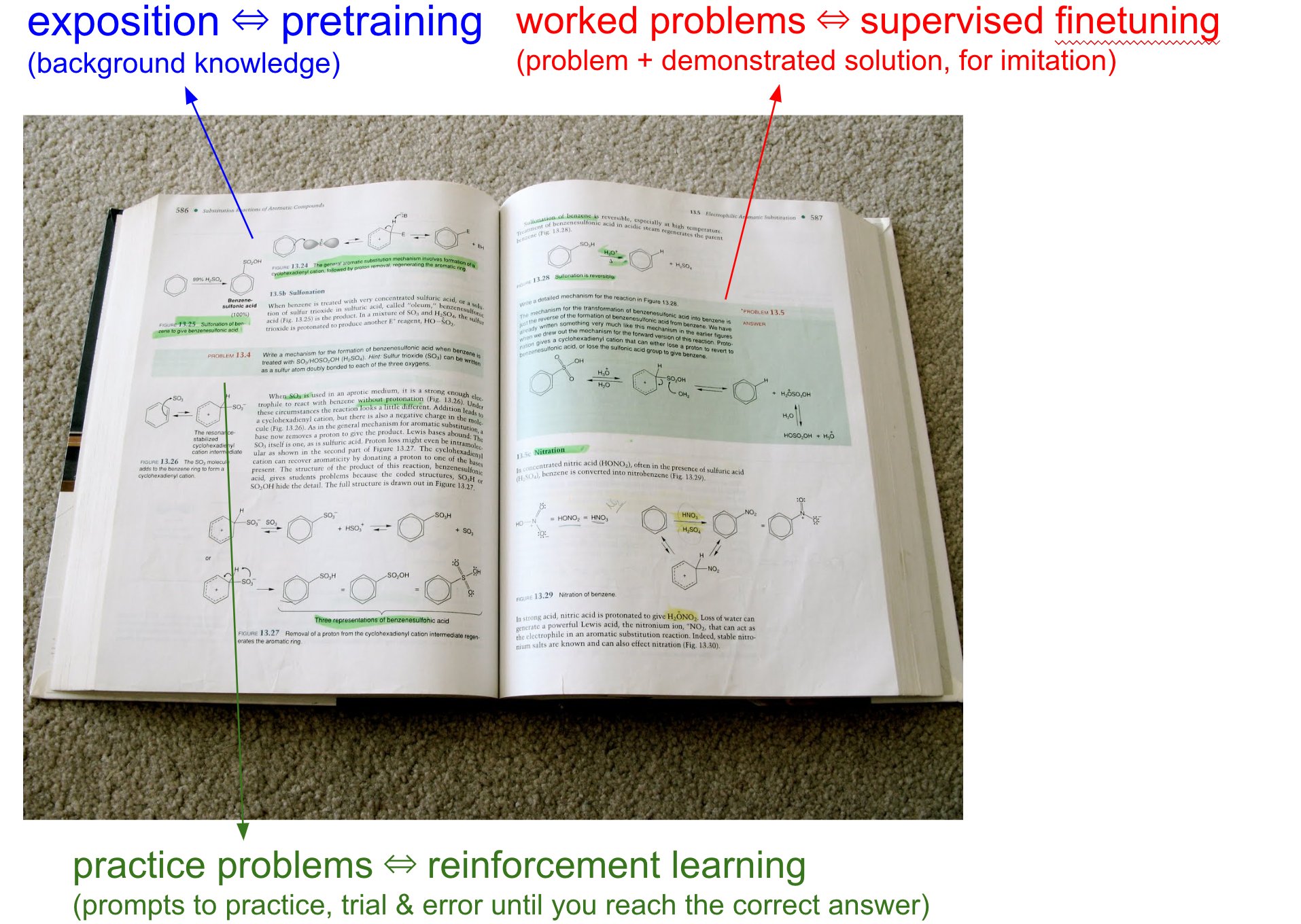
一】背景信息/讲解性内容(Background information / Exposition)
是什么?
这是教科书的核心部分,主要以解释概念、理论和背景知识为主。例如,数学教科书会先解释什么是“微积分”,它的定义、用途,以及相关公式。这部分的目的是让学生了解基础知识,并建立对主题的总体理解。
对应LLM的什么?
这是模型的【预训练阶段(Pretraining)】。在这个阶段,模型会读取大量的互联网数据(比如维基百科、新闻文章、书籍等),以此积累“背景知识”。就像我们学生时代在学习新学科时先看书了解基础内容一样,模型通过预训练掌握了自然语言的广泛知识。
为什么重要?
没有背景知识,就无法理解更复杂的内容。例如,如果学生从来没听说过“微积分”,即使给他再多的例题,他的学习也会事倍功半。同样,对于LLMs来说,预训练阶段的背景信息是理解和生成语言的基础。
二、带解答的例解(Worked Problems with Solutions)
是什么?
这是教科书中带有详细解答的例题。比如,教科书会先展示一个数学问题,然后一步步讲解如何解答。这些例题是专家的示范,告诉学生正确的思路和方法。
对应LLM的什么?
这是模型的【监督微调(Supervised Fine-tuning)】阶段。在这一阶段,专家提供“参考答案”,并教会模型如何在特定情境下生成理想的回答。例如,给模型一个问题:“如何写一封礼貌的商业邮件?” 然后训练数据里会有一个高质量、经过精心编写的参考答案。
为什么重要?
有了背景知识,学生依然需要看到“如何实际运用这些知识”的示范。通过观察专家的解题过程,学生可以模仿并内化这些思路。同样,LLMs通过监督微调学习人类语言的优雅表达和逻辑推理。
三、练习题(Practice Problems)
是什么?
这是最后一章参考答案写着「略」的练习题,通常只有问题和最终答案。例如,“求以下函数的导数”,后面只提供答案“f'(x) = 2x”。学生需要通过自己的尝试,用学到的方法解答这些问题。
对应LLM的什么?
这是模型的【强化学习(Reinforcement Learning)】阶段。在这个阶段,模型不再依赖人类直接提供的“标准解答”,而是通过反复尝试生成答案,并根据反馈(奖励或惩罚)调整它的行为。比如,在RLHF(通过人类反馈的强化学习)中,模型生成答案后,反馈系统会告诉它回答得好不好,模型通过这种反馈机制不断改进。
为什么重要?
学生只有通过练习,才能真正掌握知识,发现自己的错误并改进。同样,模型也需要通过试错来优化生成的答案质量。如果只给示范而没有练习,学生和模型都会停留在被动学习的阶段,无法主动解决问题。
四、为什么第3点(练习题)是新兴的前沿?
Karpathy指出,我们已经在第1点(预训练)和第2点(微调)上投入了大量精力,但第3点(强化学习)还处于初步发展阶段,被认为是LLMs训练的下一个重要方向。
- 对于学生来说,练习题通常是最耗时但也是最有效的学习方式。没有足够的练习,学生可能会觉得自己懂了,但实际上并没有真正掌握。
- 对于LLMs来说,强化学习可以让模型在复杂或开放性任务上进一步提升能力,而不仅仅是机械地模仿人类的回答。
五、总结:如何给LLMs“写教科书”?
Karpathy的核心观点是:训练LLMs的过程就像写教科书,我们需要同时包含三种数据:
- 背景知识(预训练):让模型了解世界的基本规则和概念。
- 示范解题(监督微调):教模型如何生成高质量的答案。
- 练习题(强化学习):通过试错让模型学会主动解决问题。(接下来的重要方向)
这种分层学习方法不仅对学生有效,对LLMs也同样适用。通过这种“教育方式”,我们可以培养出更智能、更灵活的模型,真正像一个优秀的学生一样,不仅能够理解知识,还能运用知识解决实际问题。
本文由 @Timjune 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议。












