


































关于DeepSeek的三点差异化思考:应用场景、数据服务、研发成本
DeepSeek的出现不仅在技术上取得了突破,更在应用场景、数据服务和研发成本等方面带来了新的思考。本文将从这三个维度深入分析DeepSeek的差异化优势及其对AI行业的影响,供大家参考。 蛇年除夕夜,各路自媒体忙着讨论DeepSeek:中美博弈、开源胜利、技术解析… 我今天不聊这些,来简单分析3个趋势:应用场景、数据服务、研发成本。 先回顾2个被验证了的DeepSeek的马前炮: 被验证的马前炮1:半年前,我认为国内最坚定AI技术理想主义者的公司在量化机构,DeepSeek现在证明了这个判断。DeepSeek能打开如今的局面,绝非偶然,技术认知与战略定力确实在线。 被验证的马前炮2:DeepSeek利空英伟达,利好国产化算力。发文时,英伟达创造历史最高市值蒸发纪录。大洋彼岸OpenAI、Meta们,管理成本的问题也被晾火架上烤。 然后分析3个趋势:场景、数据、成本。 一、应用场景 DeepSeek的进展,可能解锁更多高响应时效、高精度要求的复杂分析决策场景。譬如:投资决策、辅助科研、家庭教育、兵棋推演、具身智能、案件分析等等。 DeepSeek通过RL和蒸馏,较小参数的模型也可以涌现出长思维链、自我验证的能力。小参数模型的优势不仅是算力成本低,更重要的是提升响应时效、方便边缘计算。 DeepSeek开启了一个巨大的想象空间:大量原本需要深度分析推理的“慢思考”场景,很可能用“快思考”的速度就能完成。不是说DeepSeek已经做到,而是它解锁了这个趋势。 2017年Alpha Go已经可以在围棋上快速落子,围棋是有限规则的封闭场景。LLM应对更加多变的无限场景,有本书叫《有限与无限的游戏》,讲了这两种场景决策共同组成了人类社会的全部行为。 以往只有人类的认知天花板,才能够面对无限游戏做到瞬时响应,未来AI也可能做得到。 如果看过马斯克的采访,你会发现他几乎每句即兴表达,都遵循第一性原理,深度思考率接近100%,普通人类是做不到的。 福尔摩斯第一次看见华生,只看了华生一眼,就推断出他是刚从阿富汗回来的军医。这种瞬间复杂推理的能力,即便给华生1年时间也搞不定。福尔摩斯通过大量强化训练,将原本需要“慢思考”才能解决的复杂逻辑推理问题,转变为跟“快思考”一样的速度。 这种人,在专业领域内就是无敌的存在。 如果你看过《思考快与慢》,可能更容易理解。人类有两种思考系统,系统1是快思考,系统2是慢思考。人类通过长期训练,某些系统2的行为可以逐渐变得自动化,接近系统1的运作方式。复杂决策的瞬时响应,才是DeepSeek为应用场景带来的最本质改变。 二、数据服务 复杂场景、垂直领域、高质量的专业数据,比以往更加稀缺。 GPT-4o发布的时候,我抛出过这个观点: 后来Ilya等大佬也发表了类似的观点,证明我的猜测,确实通用的训练数据已接近耗尽。SFT本身有局限,如果要进一步突破上限,强化学习是为数不多的选项。 DeepSeek – R1证明仅用强化学习就可以很好地完成post – train,这样所需的标注数据规模就会下降。下降不代表没有,如果想要大模型解决更复杂的推理场景,就必须对数据结构、标注质量提高要求 —— 也就是提升评测标准。 提升哪些标准?一个是专业化,一个是拟人化。 专业化,要到什么程度?我认为不久的将来,各行业的业务专家、Leader们都要到亲自到一线实操贡献数据,萃取他们的认知复刻到大模型。通用场景数据、中低端数据外包服务将不再重要,开发者并不缺这类数据,可以通过导师模型来合成数据训练小参数模型。 高质量的专家数据将变得尤为重要,并且是经过设计、筛选、标注、核验、优化过的专家数据。 拟人化,要到什么程度?每一轮对话都像真人,而不像念稿。“像真人”这三个字的标准可以无限高,AGI也是像真人,像马斯克、王阳明一样也是像真人。到底什么样的数据,才能训练出像真人的模型?只靠微信、抖音里的那种内容数据来堆量,是没用的。如果有用,互联网大厂们的大模型性能早就可以一骑绝尘,但实际上并没有。现在一骑绝尘的是DeepSeek,AI六小虎也没有在模型水平上被大厂甩开质的差距。 现在主流的训练数据混合式是:人工数据 + 合成数据,合成数据的质量不如人类专家。所以专家们,该下场造数据了。 我认为2025年是AI数据领域的分水岭,劳动密集型的数据生意将逐渐被淘汰,转向专家密集型的高质量数据服务。这也是为什么Scale AI创始人被DeepSeek刺激,呼吁限制中国AI发展,实际上是未来Scale AI的生意更难做,真的很焦虑。 三、研发成本 头部AI公司的算力成本、团队规模会大幅控制,但人才密度会上升。 算力成本:DeepSeek展现出低成本、高ROI的模型让更多玩家看到应用场景落地的可能性,应用端玩家会更多,资金投入会更坚决。 DeepSeek刺激中美AI军备竞赛加剧,英伟达断供问题更严重。国产替代芯片需求就更加迫切,准确的说市场更加渴望低成本的高端芯片,这对国运来说是利好。 人力成本:经过DeepSeek的祛魅,AI大厂组织精简拐点已至。我想强调,不仅是硅谷,国内大厂也绝对跑不掉。 同时,更低成本、更高效率的大模型研发机会,将刺激更多新老软件公司加速布局AI,所以AI人才将呈现结构化的流动趋势。好的AI公司比以往更缺顶尖人才,100个臭皮匠不如1个诸葛亮,包括算法、工程和产品。 就像炒房、炒股,21年以来房价暴跌,一线城市的豪宅明显比刚需抗跌,豪宅自有其独立的价值逻辑。为什么炒股大家都爱龙头?表面看是人性使然,更本质的逻辑在于:龙头涨得最早,涨得最多,死得最晚。 所以,未来优秀AI公司的人才密度一定会提升,将涌现出更多小而美的组织用实力证明自己。 作者:于长弘;公众号:弘观AI 本文由 @于长弘 原创发布于人人都是产品经理。未经许可,禁止转载。 题图来自 Unsplash,基于 CC0 协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
DeepSeek的出现不仅在技术上取得了突破,更在应用场景、数据服务和研发成本等方面带来了新的思考。本文将从这三个维度深入分析DeepSeek的差异化优势及其对AI行业的影响,供大家参考。
蛇年除夕夜,各路自媒体忙着讨论DeepSeek:中美博弈、开源胜利、技术解析…
我今天不聊这些,来简单分析3个趋势:应用场景、数据服务、研发成本。
先回顾2个被验证了的DeepSeek的马前炮:

被验证的马前炮1:半年前,我认为国内最坚定AI技术理想主义者的公司在量化机构,DeepSeek现在证明了这个判断。DeepSeek能打开如今的局面,绝非偶然,技术认知与战略定力确实在线。
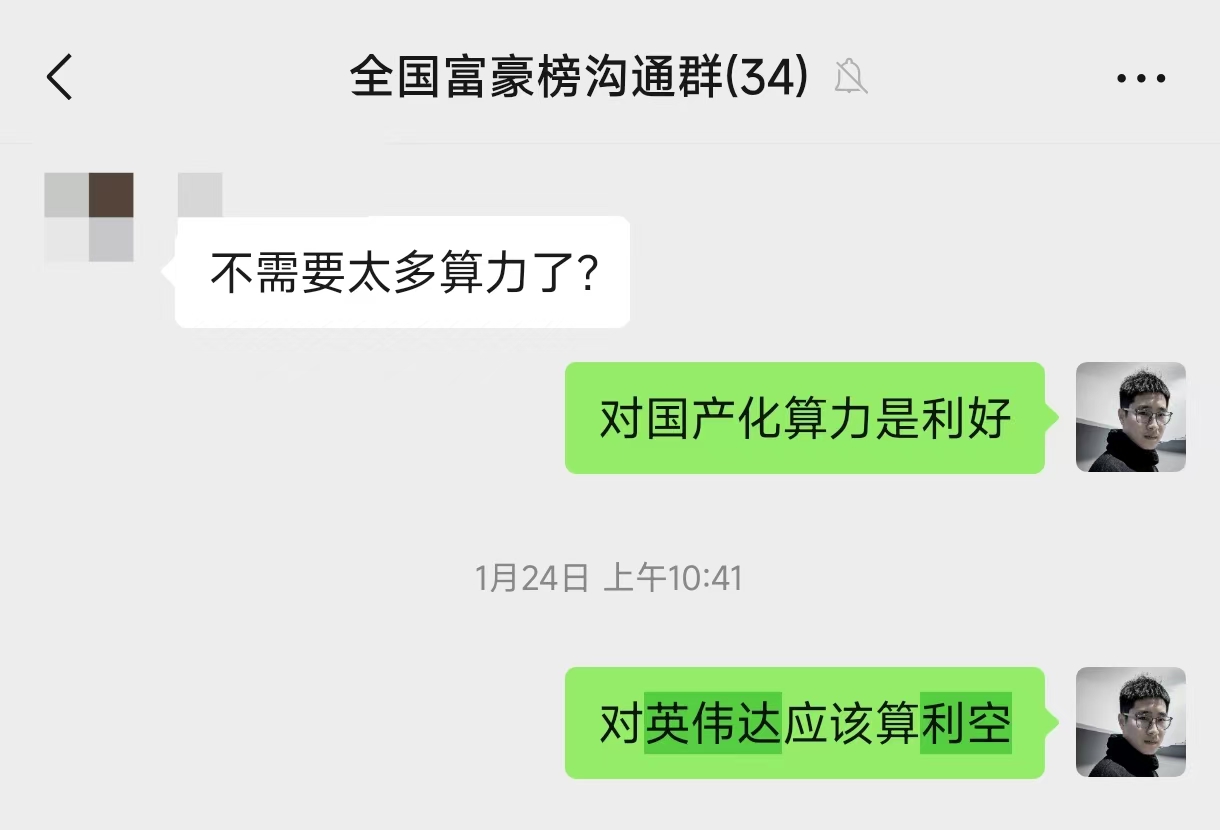
被验证的马前炮2:DeepSeek利空英伟达,利好国产化算力。发文时,英伟达创造历史最高市值蒸发纪录。大洋彼岸OpenAI、Meta们,管理成本的问题也被晾火架上烤。
然后分析3个趋势:场景、数据、成本。
一、应用场景
DeepSeek的进展,可能解锁更多高响应时效、高精度要求的复杂分析决策场景。譬如:投资决策、辅助科研、家庭教育、兵棋推演、具身智能、案件分析等等。
DeepSeek通过RL和蒸馏,较小参数的模型也可以涌现出长思维链、自我验证的能力。小参数模型的优势不仅是算力成本低,更重要的是提升响应时效、方便边缘计算。
DeepSeek开启了一个巨大的想象空间:大量原本需要深度分析推理的“慢思考”场景,很可能用“快思考”的速度就能完成。不是说DeepSeek已经做到,而是它解锁了这个趋势。
2017年Alpha Go已经可以在围棋上快速落子,围棋是有限规则的封闭场景。LLM应对更加多变的无限场景,有本书叫《有限与无限的游戏》,讲了这两种场景决策共同组成了人类社会的全部行为。
以往只有人类的认知天花板,才能够面对无限游戏做到瞬时响应,未来AI也可能做得到。
如果看过马斯克的采访,你会发现他几乎每句即兴表达,都遵循第一性原理,深度思考率接近100%,普通人类是做不到的。
福尔摩斯第一次看见华生,只看了华生一眼,就推断出他是刚从阿富汗回来的军医。这种瞬间复杂推理的能力,即便给华生1年时间也搞不定。福尔摩斯通过大量强化训练,将原本需要“慢思考”才能解决的复杂逻辑推理问题,转变为跟“快思考”一样的速度。
这种人,在专业领域内就是无敌的存在。
如果你看过《思考快与慢》,可能更容易理解。人类有两种思考系统,系统1是快思考,系统2是慢思考。人类通过长期训练,某些系统2的行为可以逐渐变得自动化,接近系统1的运作方式。复杂决策的瞬时响应,才是DeepSeek为应用场景带来的最本质改变。
二、数据服务
复杂场景、垂直领域、高质量的专业数据,比以往更加稀缺。
GPT-4o发布的时候,我抛出过这个观点:

后来Ilya等大佬也发表了类似的观点,证明我的猜测,确实通用的训练数据已接近耗尽。SFT本身有局限,如果要进一步突破上限,强化学习是为数不多的选项。
DeepSeek – R1证明仅用强化学习就可以很好地完成post – train,这样所需的标注数据规模就会下降。下降不代表没有,如果想要大模型解决更复杂的推理场景,就必须对数据结构、标注质量提高要求 —— 也就是提升评测标准。
提升哪些标准?一个是专业化,一个是拟人化。
专业化,要到什么程度?我认为不久的将来,各行业的业务专家、Leader们都要到亲自到一线实操贡献数据,萃取他们的认知复刻到大模型。通用场景数据、中低端数据外包服务将不再重要,开发者并不缺这类数据,可以通过导师模型来合成数据训练小参数模型。
高质量的专家数据将变得尤为重要,并且是经过设计、筛选、标注、核验、优化过的专家数据。
拟人化,要到什么程度?每一轮对话都像真人,而不像念稿。“像真人”这三个字的标准可以无限高,AGI也是像真人,像马斯克、王阳明一样也是像真人。到底什么样的数据,才能训练出像真人的模型?只靠微信、抖音里的那种内容数据来堆量,是没用的。如果有用,互联网大厂们的大模型性能早就可以一骑绝尘,但实际上并没有。现在一骑绝尘的是DeepSeek,AI六小虎也没有在模型水平上被大厂甩开质的差距。
现在主流的训练数据混合式是:人工数据 + 合成数据,合成数据的质量不如人类专家。所以专家们,该下场造数据了。
我认为2025年是AI数据领域的分水岭,劳动密集型的数据生意将逐渐被淘汰,转向专家密集型的高质量数据服务。这也是为什么Scale AI创始人被DeepSeek刺激,呼吁限制中国AI发展,实际上是未来Scale AI的生意更难做,真的很焦虑。
三、研发成本
头部AI公司的算力成本、团队规模会大幅控制,但人才密度会上升。
算力成本:DeepSeek展现出低成本、高ROI的模型让更多玩家看到应用场景落地的可能性,应用端玩家会更多,资金投入会更坚决。
DeepSeek刺激中美AI军备竞赛加剧,英伟达断供问题更严重。国产替代芯片需求就更加迫切,准确的说市场更加渴望低成本的高端芯片,这对国运来说是利好。
人力成本:经过DeepSeek的祛魅,AI大厂组织精简拐点已至。我想强调,不仅是硅谷,国内大厂也绝对跑不掉。
同时,更低成本、更高效率的大模型研发机会,将刺激更多新老软件公司加速布局AI,所以AI人才将呈现结构化的流动趋势。好的AI公司比以往更缺顶尖人才,100个臭皮匠不如1个诸葛亮,包括算法、工程和产品。
就像炒房、炒股,21年以来房价暴跌,一线城市的豪宅明显比刚需抗跌,豪宅自有其独立的价值逻辑。为什么炒股大家都爱龙头?表面看是人性使然,更本质的逻辑在于:龙头涨得最早,涨得最多,死得最晚。
所以,未来优秀AI公司的人才密度一定会提升,将涌现出更多小而美的组织用实力证明自己。
作者:于长弘;公众号:弘观AI
本文由 @于长弘 原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自 Unsplash,基于 CC0 协议












