


































【入门科普】关于Deepseek你肯定会关心的3个基本问题
是什么,超越ChatGPT登顶苹果App Store排行榜? 是什么,让英伟达股价暴跌近20%? 是什么,让OpenAI一边忍不住夸赞一边又无中生有地污蔑其盗窃? 是什么,让中国人春节前后欢腾不已而美国人叫苦不迭? 答案是——Deepseek的横空出世。 相信春节前后有在关注科技圈的朋友们,都会被关于Deepseek的报道、体验、分析等内容一遍遍地刷屏。这些内容,有从个人体验切入感叹Deepseek的强大,有从技术层面入手详细拆解背后的突破,也有从政治、经济、国际关系等层面剖析中美两国关系的变化。但我在春节期间回家与亲朋戚友交流发现,他们其实也有刷到相关的内容,但大多表示看不懂,或者不太清楚这款产品对于他们的日常使用有什么影响?基于此,结合本人这些天来的信息搜集和个人体验,我打算撰写这篇科普文章,希望从普通人的视角来切入,回答普通人对于Deepseek需要知道的内容。 01 Deepseek是什么 简单来说,Deepseek是由杭州深度求索公司所自研的一款通用生成式AI产品。深度求索公司在2023年7月17日正式成立,在短时间内,Deepseek发布了多个重要模型,比如Deepseek Coder、Deepseek LLM、Deepseek-V2、Deepseek-V3。2025年1月15日,搭载Deepseek-V3模型的APP上架,快速登顶苹果App Store排行榜。2025年1月20日,引起关注的Deepseek-R1模型发布并同步开源。 看到这里,也许你会发出疑问:在此之前,国内已经有多款AI产品先后发布,也号称取得良好的效果。那为什么这次Deepseek的发布,如此大的关注呢?来,我们接着往下。 02 为什么Deepseek的发布,会引起如此大的关注 Deepseek近期引发全球关注的原因,总结起来有以下4点: 1)模型的表现卓越:根据Deepseek官方和其他行业人士测试的结果,Deepseek-R1模型在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,部分测试甚至超越了OpenAI的模型。而且,Deepseek针对中文语境和特定行业需求进行了精心优化,“更适合中国宝宝体质”。 2)模型的训练方式足够创新突破:Deepseek-R1 通过独立自研的方式,在对模型训练方式、架构等进行了多项优化改进,从而大幅提升了训练效率。而且,Deepseek团队将他们的探索过程一一记录在论文当中,帮助业界指明方向。 3)模型的全面开源:Deepseek-R1模型完全开源,在遵循MIT License的规则下,为全球开发者敞开了自由使用、修改和进一步开发的大门。这种开放性极大地促进了AI领域的技术交流与创新,为整个行业的发展提供了强大助力。而这样的开源精神,曾经是OpenAI所倡导的(OpenAI的Open正是此意)。 4)模型的使用成本低:如果不想部署开源模型,Deepseek也提供了价格很低的API。这意味着普通开发者和企业可以在不承担过高费用的前提下,轻松地将Deepseek的强大功能集成到自己的应用程序或业务流程中。相信随着越来越多的落地场景探索,AI技术在应用层面会取得更大的突破。 综上所述,从国际关系视角来看,Deepseek是我国打破美国算力芯片封锁的有力动作,某种层面也给了其他行业极大的信心(任何年代,信心都是比黄金还要珍贵的事物);从技术视角来看,Deepseek使用了很低的算力成本,就达到了OpenAI-O1模型的水平,为后续的技术迭代指明了方向,而且它还对外开源了;从应用视角来看,Deepseek相当于让每一位使用者都可以使用到第一梯队的AI产品,实现“技术平权”。 或许,你不负责技术实现,也不关心国家大事,但Deepseek的问世,也意味着我们使用AI的方式也有了变化,这就跟我们密切相关了。接下来,我们来看看,对于普通人而言,Deepseek发布后,使用AI的方式有哪些改变。 03 Deepseek发布后,我们使用AI的方式有哪些变化 我们先来看看,在Deepseek发布之前(或者说是OpenAI-o1发布之前),在普罗大众层面传播的AI使用方式是怎样的。以下是我在微信搜索“提示词”的一些典型文章截图。 这些提示词教学,无一不是在强调提示词的框架性。但从Deepseek-R1发布的那一刻起,这些文章的内容就已经不再适用了。关于这一点的原因,我在我自己的AI课程里也有介绍,倒不是说这些内容是错误的,而是它们其实是属于提示词工程(Prompt Engineering)范畴的内容。各类专业框架,实质上是给AI生成过程提供严谨、完整的参考信息和思考链路,从而追求极致的生成质量。但是,Deepseek-R1以及之前的OpenAI-O1,都是推理型模型,自带思维链的能力。对于没有经过深度钻研提示词工程的普罗大众而言,盲目套用这些框架,只会干扰AI的思考结果,得不偿失。就好比手动档的汽车,需要驾驶员自己判断何时切换档位,为此也有各路老司机总结的一些判断准则。但是,盲目将这些判断套用到自动档上,显然是适得其反。 所谓思维链(CoT,Chain-of-Thought),就是让模型在给出答案前进行逐步的思考与推理,并将这一过程显式呈现,仿佛是人类将复杂的思考路径拆解展示。例如在解决多步数学问题或复杂逻辑推理时,模型按照逻辑顺序逐步分析,先理解问题,再寻找关键条件,逐步推导直至得出结论。这种方式不仅增强了模型的可解释性,使人们能够清晰了解答案的由来,同时也提升了解决复杂问题的能力。 那么,在自带思维链的Deepseek面前,我们使用AI方式,应该如何改变?比之“改变”,我认为准确的说法是“回归”,也就是回归到平常的自然语言上。用大白话解答就是三个字—— 说——人——话—— 展开来讲就是,忘掉以往学习软件那一套“指令式交互”,而是回归到完成任务本身。也就是我们把AI看成是一名“无所不知、非常聪明、听懂人话、刚进公司”的实习生,然后想想,如果你跟这样一名实习生交代任务,你会怎么交代?是不是要把任务讲清楚,然后要提供足够的参考信息,尽可能明确各类要求,必要的时候还可以提供一些参考例子? 是的,跟AI下达指令时,不要再去纠结这样说“正不正确”,而是关注这样说“齐不齐全”。只要信息给得足够齐全,Deepseek会自己拆解问题逐步思考给出回答。 至于具体的使用Prompt的技巧,这足够单独成文了。限于篇幅,我们在这里就不展开,如果大家比较感兴趣,可以给在下多多点赞,我在后续安排上。这里,我就给大家展示一个我自己使用Deepseek的例子,就是让AI依据词牌写词(补充一下,我很喜欢用给AI出写古代诗词,基本上能很好地看出是套了ChatGPT还是自己训练,前者对中文的理解没有这么透彻)。 我的Prompt如下: 你要参考水调歌头的词牌,以当前人工智能的发展为主题,写一首歌,我希望你告诉我你主要参考了哪些作者的作品,参考了哪些内容。 是不是感觉这段Prompt平平无奇,甚至有些简陋。是的,我是故意为之,当时也是想看看Deepseek的思维链表现。来,我们再来看看Deepseek的思考过程(内容较多,我就直接截图)。 看完后我直呼好家伙,Deepseek展示了它的完整思考过程。首先挑选它认为合适的参考作品,然后确定主题内容,押韵韵脚和用词的选择,最后还会检查是否符合格律要求。这简直就跟人类在思考创作一阙词作的过程一模一样。 不过,我还有后招,按我以前的经验,AI大概率是处理不好中文的押韵问题的(我曾经为此跟ChatGPT及多款AI来回拉扯了几轮都没有达成)。大家注意看下,“秋”和“浮”是不押韵的,当时我心里想,“哈哈,还不让我抓住你的小瓣子”。于是,我就在对话里指出,“上面的作品,秋和浮,不押韵”。 然而,结果证明是我肤浅了。来,我们来看下Deepseek对此的回应。 原来是我低估了,Deepseek指出,它参考了《词林正韵》,“流”和“浮”这两个字在古代的读音是押韵的,“浮”字的宋代实际读音近「fəu」(这点我作为一名广东人还是能理解的,实际上这两个字在粤语里的确还是押韵的)。而且,它还补充说,“苏轼原词「天」「年」「寒」「间」同样存在古今音变问题”,这多少是有点傲娇了哈哈。不过,它最后还是按照要求进行了调整。 之后,我在多轮对话中,陆续还提了“我希望就以现代普通话为标准就行”、“最后两句的结尾都是同一个字“舟”,可否避免?”等要求。这是我和Deepseek的最后一轮对话。 我虽已练就与AI对话的能力,但在与Deepseek对话的过程中,我依然有一种“惊喜感”,一种“你太会了”的感受。可以说,Deepseek代表着人类在AI领域的探索又前进了一步。我之前曾有总结“AI生成结果再丰富再优质,最终的判断与选择权在使用者。只有使用者的认知水平足够高,才能辨别AI结果的优与劣。”这既是对AI没有判断立场的补充,又仿佛是人类的挽尊。 最后总结一下,我们在面对类似Deepseek这样自带思维链的推理型AI模型,在实际对话的过程中,不必关注Prompt的框架性,而是要“说人话”,也就是使用自然语言来表达清楚我们的任务。重点关注提供的信息,对于完成任务而言是否有帮助,是否足够齐全。至于过程中的问题拆解,就尽管交给AI即可。 作者:产品经理崇生,公众号:崇生的黑板报 本文由 @产品经理崇生 原创发布于人人都是产品经理。未经作者许可,禁止转载 题图来自 unsplash,基于CC0协议 该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。


是什么,超越ChatGPT登顶苹果App Store排行榜?
是什么,让英伟达股价暴跌近20%?
是什么,让OpenAI一边忍不住夸赞一边又无中生有地污蔑其盗窃?
是什么,让中国人春节前后欢腾不已而美国人叫苦不迭?
答案是——Deepseek的横空出世。
相信春节前后有在关注科技圈的朋友们,都会被关于Deepseek的报道、体验、分析等内容一遍遍地刷屏。这些内容,有从个人体验切入感叹Deepseek的强大,有从技术层面入手详细拆解背后的突破,也有从政治、经济、国际关系等层面剖析中美两国关系的变化。但我在春节期间回家与亲朋戚友交流发现,他们其实也有刷到相关的内容,但大多表示看不懂,或者不太清楚这款产品对于他们的日常使用有什么影响?基于此,结合本人这些天来的信息搜集和个人体验,我打算撰写这篇科普文章,希望从普通人的视角来切入,回答普通人对于Deepseek需要知道的内容。
01 Deepseek是什么
简单来说,Deepseek是由杭州深度求索公司所自研的一款通用生成式AI产品。深度求索公司在2023年7月17日正式成立,在短时间内,Deepseek发布了多个重要模型,比如Deepseek Coder、Deepseek LLM、Deepseek-V2、Deepseek-V3。2025年1月15日,搭载Deepseek-V3模型的APP上架,快速登顶苹果App Store排行榜。2025年1月20日,引起关注的Deepseek-R1模型发布并同步开源。
看到这里,也许你会发出疑问:在此之前,国内已经有多款AI产品先后发布,也号称取得良好的效果。那为什么这次Deepseek的发布,如此大的关注呢?来,我们接着往下。
02 为什么Deepseek的发布,会引起如此大的关注
Deepseek近期引发全球关注的原因,总结起来有以下4点:
1)模型的表现卓越:根据Deepseek官方和其他行业人士测试的结果,Deepseek-R1模型在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,部分测试甚至超越了OpenAI的模型。而且,Deepseek针对中文语境和特定行业需求进行了精心优化,“更适合中国宝宝体质”。

2)模型的训练方式足够创新突破:Deepseek-R1 通过独立自研的方式,在对模型训练方式、架构等进行了多项优化改进,从而大幅提升了训练效率。而且,Deepseek团队将他们的探索过程一一记录在论文当中,帮助业界指明方向。
3)模型的全面开源:Deepseek-R1模型完全开源,在遵循MIT License的规则下,为全球开发者敞开了自由使用、修改和进一步开发的大门。这种开放性极大地促进了AI领域的技术交流与创新,为整个行业的发展提供了强大助力。而这样的开源精神,曾经是OpenAI所倡导的(OpenAI的Open正是此意)。
4)模型的使用成本低:如果不想部署开源模型,Deepseek也提供了价格很低的API。这意味着普通开发者和企业可以在不承担过高费用的前提下,轻松地将Deepseek的强大功能集成到自己的应用程序或业务流程中。相信随着越来越多的落地场景探索,AI技术在应用层面会取得更大的突破。
综上所述,从国际关系视角来看,Deepseek是我国打破美国算力芯片封锁的有力动作,某种层面也给了其他行业极大的信心(任何年代,信心都是比黄金还要珍贵的事物);从技术视角来看,Deepseek使用了很低的算力成本,就达到了OpenAI-O1模型的水平,为后续的技术迭代指明了方向,而且它还对外开源了;从应用视角来看,Deepseek相当于让每一位使用者都可以使用到第一梯队的AI产品,实现“技术平权”。
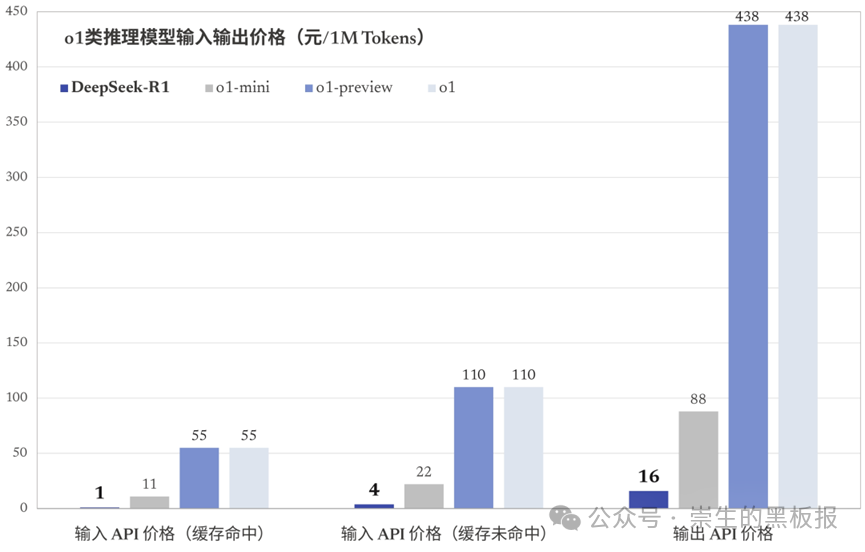
或许,你不负责技术实现,也不关心国家大事,但Deepseek的问世,也意味着我们使用AI的方式也有了变化,这就跟我们密切相关了。接下来,我们来看看,对于普通人而言,Deepseek发布后,使用AI的方式有哪些改变。
03 Deepseek发布后,我们使用AI的方式有哪些变化
我们先来看看,在Deepseek发布之前(或者说是OpenAI-o1发布之前),在普罗大众层面传播的AI使用方式是怎样的。以下是我在微信搜索“提示词”的一些典型文章截图。


这些提示词教学,无一不是在强调提示词的框架性。但从Deepseek-R1发布的那一刻起,这些文章的内容就已经不再适用了。关于这一点的原因,我在我自己的AI课程里也有介绍,倒不是说这些内容是错误的,而是它们其实是属于提示词工程(Prompt Engineering)范畴的内容。各类专业框架,实质上是给AI生成过程提供严谨、完整的参考信息和思考链路,从而追求极致的生成质量。但是,Deepseek-R1以及之前的OpenAI-O1,都是推理型模型,自带思维链的能力。对于没有经过深度钻研提示词工程的普罗大众而言,盲目套用这些框架,只会干扰AI的思考结果,得不偿失。就好比手动档的汽车,需要驾驶员自己判断何时切换档位,为此也有各路老司机总结的一些判断准则。但是,盲目将这些判断套用到自动档上,显然是适得其反。
所谓思维链(CoT,Chain-of-Thought),就是让模型在给出答案前进行逐步的思考与推理,并将这一过程显式呈现,仿佛是人类将复杂的思考路径拆解展示。例如在解决多步数学问题或复杂逻辑推理时,模型按照逻辑顺序逐步分析,先理解问题,再寻找关键条件,逐步推导直至得出结论。这种方式不仅增强了模型的可解释性,使人们能够清晰了解答案的由来,同时也提升了解决复杂问题的能力。
那么,在自带思维链的Deepseek面前,我们使用AI方式,应该如何改变?比之“改变”,我认为准确的说法是“回归”,也就是回归到平常的自然语言上。用大白话解答就是三个字——
说——人——话——
展开来讲就是,忘掉以往学习软件那一套“指令式交互”,而是回归到完成任务本身。也就是我们把AI看成是一名“无所不知、非常聪明、听懂人话、刚进公司”的实习生,然后想想,如果你跟这样一名实习生交代任务,你会怎么交代?是不是要把任务讲清楚,然后要提供足够的参考信息,尽可能明确各类要求,必要的时候还可以提供一些参考例子?
是的,跟AI下达指令时,不要再去纠结这样说“正不正确”,而是关注这样说“齐不齐全”。只要信息给得足够齐全,Deepseek会自己拆解问题逐步思考给出回答。
至于具体的使用Prompt的技巧,这足够单独成文了。限于篇幅,我们在这里就不展开,如果大家比较感兴趣,可以给在下多多点赞,我在后续安排上。这里,我就给大家展示一个我自己使用Deepseek的例子,就是让AI依据词牌写词(补充一下,我很喜欢用给AI出写古代诗词,基本上能很好地看出是套了ChatGPT还是自己训练,前者对中文的理解没有这么透彻)。
我的Prompt如下:
你要参考水调歌头的词牌,以当前人工智能的发展为主题,写一首歌,我希望你告诉我你主要参考了哪些作者的作品,参考了哪些内容。
是不是感觉这段Prompt平平无奇,甚至有些简陋。是的,我是故意为之,当时也是想看看Deepseek的思维链表现。来,我们再来看看Deepseek的思考过程(内容较多,我就直接截图)。

看完后我直呼好家伙,Deepseek展示了它的完整思考过程。首先挑选它认为合适的参考作品,然后确定主题内容,押韵韵脚和用词的选择,最后还会检查是否符合格律要求。这简直就跟人类在思考创作一阙词作的过程一模一样。
不过,我还有后招,按我以前的经验,AI大概率是处理不好中文的押韵问题的(我曾经为此跟ChatGPT及多款AI来回拉扯了几轮都没有达成)。大家注意看下,“秋”和“浮”是不押韵的,当时我心里想,“哈哈,还不让我抓住你的小瓣子”。于是,我就在对话里指出,“上面的作品,秋和浮,不押韵”。
然而,结果证明是我肤浅了。来,我们来看下Deepseek对此的回应。

原来是我低估了,Deepseek指出,它参考了《词林正韵》,“流”和“浮”这两个字在古代的读音是押韵的,“浮”字的宋代实际读音近「fəu」(这点我作为一名广东人还是能理解的,实际上这两个字在粤语里的确还是押韵的)。而且,它还补充说,“苏轼原词「天」「年」「寒」「间」同样存在古今音变问题”,这多少是有点傲娇了哈哈。不过,它最后还是按照要求进行了调整。
之后,我在多轮对话中,陆续还提了“我希望就以现代普通话为标准就行”、“最后两句的结尾都是同一个字“舟”,可否避免?”等要求。这是我和Deepseek的最后一轮对话。
我虽已练就与AI对话的能力,但在与Deepseek对话的过程中,我依然有一种“惊喜感”,一种“你太会了”的感受。可以说,Deepseek代表着人类在AI领域的探索又前进了一步。我之前曾有总结“AI生成结果再丰富再优质,最终的判断与选择权在使用者。只有使用者的认知水平足够高,才能辨别AI结果的优与劣。”这既是对AI没有判断立场的补充,又仿佛是人类的挽尊。
最后总结一下,我们在面对类似Deepseek这样自带思维链的推理型AI模型,在实际对话的过程中,不必关注Prompt的框架性,而是要“说人话”,也就是使用自然语言来表达清楚我们的任务。重点关注提供的信息,对于完成任务而言是否有帮助,是否足够齐全。至于过程中的问题拆解,就尽管交给AI即可。
作者:产品经理崇生,公众号:崇生的黑板报
本文由 @产品经理崇生 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自 unsplash,基于CC0协议












