


































AI又颠覆了?浅谈如何科学祛魅,评估业务赋能程度
AI的快速迭代也让许多人感到困惑:如何科学评估AI对业务的实际赋能程度?本文将分享一套基于业务需求的AI评测方法,帮助读者通过量化指标和定制化测试,科学地评估AI工具在特定业务场景中的适用性和效果。 过年期间想必各位都被Deepseek刷屏了吧,各种铺天盖地的消息席卷而来,什么干掉OpenAI、干掉美国、干掉所有人。 虽然实际上先干掉的是Deepseek的服务器。 这说明巨大的流量背后是人们对AI巨大的期望,或者是困惑——“如今的AI能怎么样赋能我/我的团队/我的企业?” 关于这个困惑,个人觉得不仅仅是在Deepseek这一波里面存在,而是在AI的迭代日新月异的当下,每一个人无时无刻都会沉浸在类似于“AI发展到哪里了”、“现在AI现在对我有什么用”的焦虑当中。因为如果等到AI应用在我们自身的领域普及的时候,已经是“我们要被淘汰”的时候了。 就拿我经常折腾的AI视频来举例子。 2024年AI视频生成技术可谓发展超级迅猛,涌现了不少AI视频生成厂商,比如可灵、Sora、即梦、Pika……一开始各家的能力还非常垃圾,我还以为“AI视频领域或许还要等个几年才能在业务用上”,但是仅仅过了半年,业务的同学就已经可以把AI视频结合业务用起来了。 放点成品可能直观点,同样是生成皇宫,如今的可灵简直是吊打半年前的可灵。 这意味着,身处浪潮之中的每个人,如果不想被淘汰,必须得时事跟进,定期测试。这里的测试目的在于: 1.了解AI厂商从X.0版本迭代到X.1版本,对于我们的业务而言,提升了什么? 2.了解多个AI厂商之间最新版本的区别,哪个厂商对于我们的业务而言具有更高的效用? 从而保证我们能够“贴合业务需要”地跟进“AI的发展” 可能会有人提出疑问。 “厂商不是有更新公告等说明吗?” 我们无法从厂商给出的介绍中获取答案,因为他们只会含糊地描述为“更好”(如下图),那在哪些方面更好呢?有多好呢?这些我们是没法知道的。 “不是有专门的评测机构吗?” 目前的确有一些组织会进行AI大模型评分,通过一系列标准化的测试来衡量其在不同任务上的表现。比如SuperCLUE这个第三方评测机构,就会定期出题进行测试,从而判断各家大模型在他们定制的维度下的表现,并得出最终的评分。 但是这种方式仅仅能帮我们快速筛选掉一些较差的大模型厂商,而其中的评测结果不一定适用于我们,因为评测的维度、评测的题目不一定符合我们的需求。 比如我们是电商行业,我们使用AI视频的需求是“商品展示视频”,在这个场景下,我们对AI视频的“外观遵循能力”的要求是“XX类商品”的外观遵循准确。所以基于“指定题集”的评测结果,可能对人物、动物、汽车等常见的主体外观识别准确,但是在“XX类商品”上不一定准确,所以不一定适合我们的业务场景。 正如智源研究院副院长兼总工程师林咏华所言,“榜单排名不应作为评价模型的唯一标准。”林咏华认为,用户在选择模型时,应根据自身需求和应用场景,综合考虑模型的各项指标,而非仅仅关注排名。 而且对于天天“颠覆”的AI行业来说,依靠第三方平台不能让我们快速跟进,比如像是SuperCLUE这种平台,顶多一个月一次评测。 所以这种情况下,我们还是需要进行基于业务的定制化AI评测,用我们专有的业务题库。下面便分享下我的一些心得。 01 测试核心逻辑 先简单讲讲核心的步骤,重点在于结合业务需求,设计可被量化的“测试指标”,并设计可分为多个难度的题集。拆分成步骤的话,主要是: 1.初筛; 2.工具熟悉; 3.设计评测指标; 4.选取测试样本; 5.执行并记录评分; 02 测试说明及案例 那下面具体讲一下每一步是如何进行的。 1. 初筛——通过信息采集渠道初筛 我们没法全部AI厂商都进行测试,因为测试是需要一定的人力成本以及工具购买成本,所以一开始要通过一些可靠的信息源初筛,避免过度浪费时间。 那么,有那些可靠的信息源呢? 1)专门的评测机构 正如前文提到,专门的评测机构会进行大批量的系统化的测试,我们可以通过他们的测试结果了解到目前能力最强的是什么AI厂商。但是可能会出现排在前面的几个AI分数差不多的情况 这种情况下,我们就要看评测机构的各评分项的分值情况,来看看“哪家厂商在我们需要的能力上分值更高”。 图来源于SuperCLUE官网 比如我们做电商的,我们往往需要“商品展示视频中的商品不要变形”,所以会更看重“外观遵循”这项能力。由此,通过筛选“外观遵循”的分值,我们会发现Luma的分值是最高的。那么我们便可优先测试Luma。 2)自媒体评测 我们也可以通过各种AI自媒体的评测来获知“哪些AI可能更适合我们”。但是并非所有自媒体都要相信,我们要警惕以下账号: 天塌党:指天天喊着行业颠覆,XXX行业又要失业的一些自媒体,这些人往往AI都没用过几次,对实际业务也不了解,看到AI厂商的更新公告和测试案例就“高潮”了,上来就劈头盖脸地说大伙要完蛋 以博取流量。 广告党:这些号往往会在某家厂商发布某项新功能的适合发视频,其目的就是宣扬别的厂商的新功能。这些号的内容往往会“避重就轻”,给到的案例都是好的案例,对于AI实际存在的问题避而不谈,从而误导用户“这个AI号真牛啊”。 我们选择自媒体的时候,要看看“他们是否有一定的粉丝基础”、“描述方式是否客观”、“是否有足够的案例”,从而判断他们的话是否可信。 3)官方案例 大部分厂商都会放出一定量的官方案例,有的甚至会有官方社区(比如AI视频厂商的创意圈)。 因为这些案例必定是经过精挑细选的,所以我们可从中看到AI厂商能力的“上限”,也能和其他厂商进行快速的横向对比。 4)AI社区:遇事不决,就问群里的大佬。 在群聊里,我们可以问到一些大佬最真实的使用体验,通过这些反馈,我们可以快速获悉“AI在实际应用中的表现”,从而判断AI是否对我们的业务有帮助。 所以在AI时代尽可能地拓展信息源,是一项非常重要的事情。 2. 工具熟悉——熟悉工具才能客观地测试 通过初筛选出的AI工具后,我们需要对这些工具有初步的认知。不然你可能连工具的50%力量都没发挥出来,却由于“自己的不熟悉”而给“一个优质的工具”评判为“不合适”。 那如何快速熟悉工具呢? 在这个时代,我们最不怕的就是学不会工具了。因为现在“教大家用AI赚钱的人”可能比“用AI赚钱的人”还要多,随便上网一搜,全都是“教你怎么用XX AI”的教程。更懒一点的,随便上个知识付费网站,都还能找到手把手教你的。 而且,官方也会“想尽办法教会你”,因为用户用得越好,便能通过优质案例吸引更多用户,带来更多付费。 像是可灵、豆包,他们都提供了“用户教育”相关的功能。 可灵有官方教程功能、创意圈的“一键同款”功能…… 豆包则提供了提示词示例功能,用于告知用户“该AI能做什么”。 但无论如何,最重要的是,我们要亲自上手使用工具。弄脏自己双手,亲自体验,不要纸上谈兵。 3. 设计评测指标——设计“描述工具是否适合我们”的量化标准: 由于我们是需要对多个AI厂商进行对比,而我们对比的内容是偏主观的“AI生成内容”,因此我们需要设计一套评测指标,用来描述“工具是否适合我们”。 那么如何设计这套指标呢?以下为个人梳理的步骤~ 1)梳理“满足业务需求的标准”。 并非所有人都能立马把一个主观的事物抽象出“客观的评价”的。所以这里有个技巧,我们先问问自己“到底AI生成成什么样,才能视为满足业务需求呢”? 通过这个过程,我们可以去想象 或者找到一些满足业务需求的案例,从中找到一些共性。 比如在营销文案生成场景,营销文案必须是“创意独特的”、“满足目标用户群体需求的”、“引起情感共鸣的”、“语言流畅清晰的”。 比如在商品展示视频(图生视频)生成场景,生成的成品视频必须是“清晰的”、“商品外观前后一致的”、“动作指令一致的”。 2)从标准倒推“评测维度”。 当我们写好“标准”后,我们倒推“评测维度”就很简单了。只需要使用一个中性词汇对其描述即可。 继续拿上面两个案例举例~ 比如在营销文案生成场景~ 比如在商品展示视频(图生视频)生成场景~ 3)设计每个维度的分值及其分段定义。 最后,我们需要设计每个维度的分值定义。这里定义需要把主观的事情进行“量化”,从而保证最终的分值是客观的,也保证即使进行团队评测,也能够较为公正地进行AI工具评测。 对主观事物进行量化的方法无非是找到其中可被量化定义的事物。 我们可以尝试从中找到可被量化定义的事物,比如一段文章中的“错别字”、“关键词”数量,比如一段文章中有无“XX错误”,这些内容可以通过客观的标准进行描述,从而统计其中的数量。 像是“错别字”、“关键词”这类内容,是能够客观地定义“错别字”、“关键词”,并从中数出这些内容的数量。而像是“美丽画面”的数量这种“主观定义”的事物,则无法用于判断维度分值的定义。 比如错别字数量可以用来衡量“生成正确性”,并得出以下标准。 生成正确性 高分(8-10分):少于2个错别字。 中等(4-7分):有3-4个错别字。 低分(0-3分):大于5个错别字。 比如“画面与指令不符合区域数量”可以用来视频生成AI的“外观指令遵循”,并得出以下标准。 外观指令遵循 高分(8-10分):少于或等于1个画面与指令不符合区域数。 中等(4-7分):少于或等于4个画面与指令不符合区域数。 低分(0-3分):4个以上个画面与指令不符合区域数。 比如AI是否准确分类,这种维度其中只有“准”与“不准”的说法。 分类正确性 高分(10分):准确分类。 低分(0分):分类不准确。 当然,以上步骤完全可以借力,比如: 1)AI代劳: AI在这些方面还是挺在行的,写的清晰又全面,我们可以直接描述下业务,把这个问题甩给AI。 我是一个电商行业的从业者,我想测试deepseek在广告文案生成上的效果,现在需要几个评价维度,帮助我用分数来衡量deepseek在这里的表现。 请你写出至少5个评价维度~并给出这5个维度里面,低分、中等、高分的量化定义。 注意,定义需要可量化! 2)抄第三方评测机构标准: 直接基于评测机构的维度进行二次优化和修改,修改的内容可以结合业务的实际需求进行调整。 图来源于SuperCLUE官网 比如视频生成场景,我们可以先参考SuperCLUE的指标,列出“主体外观画质”、“背景画面画质”、“主体外观遵循能力”、“背景画面遵循能力”、“数量精准性”、“空间关系”、“运镜准确性”、“单一主体动态准确性”、“多个主体动态准确性”…… 然后假设我们是电商业务的“商品展示”场景,那边便可拎出“主体外观画质”、“主体外观遵循能力”、“运镜准确性”、“单一主体动态准确性”这几个维度作为我们的测试重点。 4. 选取测试样本——选择充分且合适的样本; 基于评测指标,使用具有代表性的测试素材在不同方案上进行测试。这些素材需要具备以下特征: 1)样本量充分: 我们的样本不能只有仅仅一两个,需要达到一定的量级,使得AI的能力能被充分测试。 2)贴合评测指标: 所选的样本需要能够对评测指标进行检验,比如测试AI编程水平的时候,要检测其BUG识别能力的时候,至少需要样本中“有BUG”。 3)对不同难度的样本进行分类: 多个样本其实也会有难度之别,所以我们需要对题库进行难度分类,避免题目过难,评测结果分值偏低,最终看不出AI的作用。 对题库进行难度分类的方式和“评测指标设计”中的“分值设置”思路类似,是找到其中的可量化点,然后对其进行难度划分。 比如评测文本AI的“错字识别”能力时,可以直接按样本中的错字数量进行难度划分。 错字识别 高难度:大于5个错字。 中难度:3~4个错字。 低难度:1~2个错字。 5. 执行并记录评分 最后,就是将样本在AI工具上批量测试,并记录相关结论和截图。由于这一部分评价偏主观,最好由同一批人进行评价。 如果样本中存在不同难度,则最好分批次进行测试,分别记录不同难度下的分值,以更精细地判断AI的能力边界。 小结 至此,个人对于AI评测的经验便汇总完了,核心是结合业务需求,设计可被量化的“测试指标”,并设计

AI的快速迭代也让许多人感到困惑:如何科学评估AI对业务的实际赋能程度?本文将分享一套基于业务需求的AI评测方法,帮助读者通过量化指标和定制化测试,科学地评估AI工具在特定业务场景中的适用性和效果。

过年期间想必各位都被Deepseek刷屏了吧,各种铺天盖地的消息席卷而来,什么干掉OpenAI、干掉美国、干掉所有人。
虽然实际上先干掉的是Deepseek的服务器。
这说明巨大的流量背后是人们对AI巨大的期望,或者是困惑——“如今的AI能怎么样赋能我/我的团队/我的企业?”
关于这个困惑,个人觉得不仅仅是在Deepseek这一波里面存在,而是在AI的迭代日新月异的当下,每一个人无时无刻都会沉浸在类似于“AI发展到哪里了”、“现在AI现在对我有什么用”的焦虑当中。因为如果等到AI应用在我们自身的领域普及的时候,已经是“我们要被淘汰”的时候了。
就拿我经常折腾的AI视频来举例子。
2024年AI视频生成技术可谓发展超级迅猛,涌现了不少AI视频生成厂商,比如可灵、Sora、即梦、Pika……一开始各家的能力还非常垃圾,我还以为“AI视频领域或许还要等个几年才能在业务用上”,但是仅仅过了半年,业务的同学就已经可以把AI视频结合业务用起来了。
放点成品可能直观点,同样是生成皇宫,如今的可灵简直是吊打半年前的可灵。

这意味着,身处浪潮之中的每个人,如果不想被淘汰,必须得时事跟进,定期测试。这里的测试目的在于:
1.了解AI厂商从X.0版本迭代到X.1版本,对于我们的业务而言,提升了什么?
2.了解多个AI厂商之间最新版本的区别,哪个厂商对于我们的业务而言具有更高的效用?
从而保证我们能够“贴合业务需要”地跟进“AI的发展”
可能会有人提出疑问。
“厂商不是有更新公告等说明吗?”
我们无法从厂商给出的介绍中获取答案,因为他们只会含糊地描述为“更好”(如下图),那在哪些方面更好呢?有多好呢?这些我们是没法知道的。
“不是有专门的评测机构吗?”
目前的确有一些组织会进行AI大模型评分,通过一系列标准化的测试来衡量其在不同任务上的表现。比如SuperCLUE这个第三方评测机构,就会定期出题进行测试,从而判断各家大模型在他们定制的维度下的表现,并得出最终的评分。
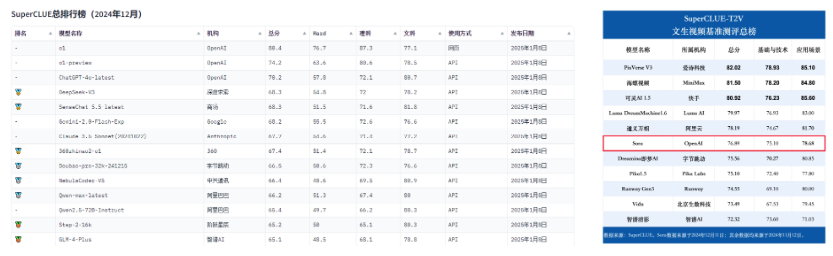
但是这种方式仅仅能帮我们快速筛选掉一些较差的大模型厂商,而其中的评测结果不一定适用于我们,因为评测的维度、评测的题目不一定符合我们的需求。
比如我们是电商行业,我们使用AI视频的需求是“商品展示视频”,在这个场景下,我们对AI视频的“外观遵循能力”的要求是“XX类商品”的外观遵循准确。所以基于“指定题集”的评测结果,可能对人物、动物、汽车等常见的主体外观识别准确,但是在“XX类商品”上不一定准确,所以不一定适合我们的业务场景。
正如智源研究院副院长兼总工程师林咏华所言,“榜单排名不应作为评价模型的唯一标准。”林咏华认为,用户在选择模型时,应根据自身需求和应用场景,综合考虑模型的各项指标,而非仅仅关注排名。
而且对于天天“颠覆”的AI行业来说,依靠第三方平台不能让我们快速跟进,比如像是SuperCLUE这种平台,顶多一个月一次评测。
所以这种情况下,我们还是需要进行基于业务的定制化AI评测,用我们专有的业务题库。下面便分享下我的一些心得。
01 测试核心逻辑
先简单讲讲核心的步骤,重点在于结合业务需求,设计可被量化的“测试指标”,并设计可分为多个难度的题集。拆分成步骤的话,主要是:
1.初筛;
2.工具熟悉;
3.设计评测指标;
4.选取测试样本;
5.执行并记录评分;
02 测试说明及案例
那下面具体讲一下每一步是如何进行的。
1. 初筛——通过信息采集渠道初筛
我们没法全部AI厂商都进行测试,因为测试是需要一定的人力成本以及工具购买成本,所以一开始要通过一些可靠的信息源初筛,避免过度浪费时间。
那么,有那些可靠的信息源呢?
1)专门的评测机构
正如前文提到,专门的评测机构会进行大批量的系统化的测试,我们可以通过他们的测试结果了解到目前能力最强的是什么AI厂商。但是可能会出现排在前面的几个AI分数差不多的情况
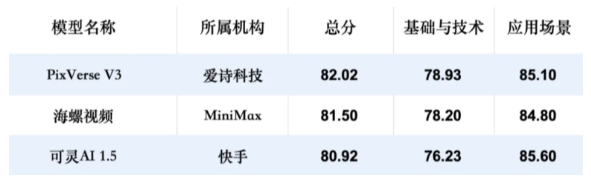
这种情况下,我们就要看评测机构的各评分项的分值情况,来看看“哪家厂商在我们需要的能力上分值更高”。
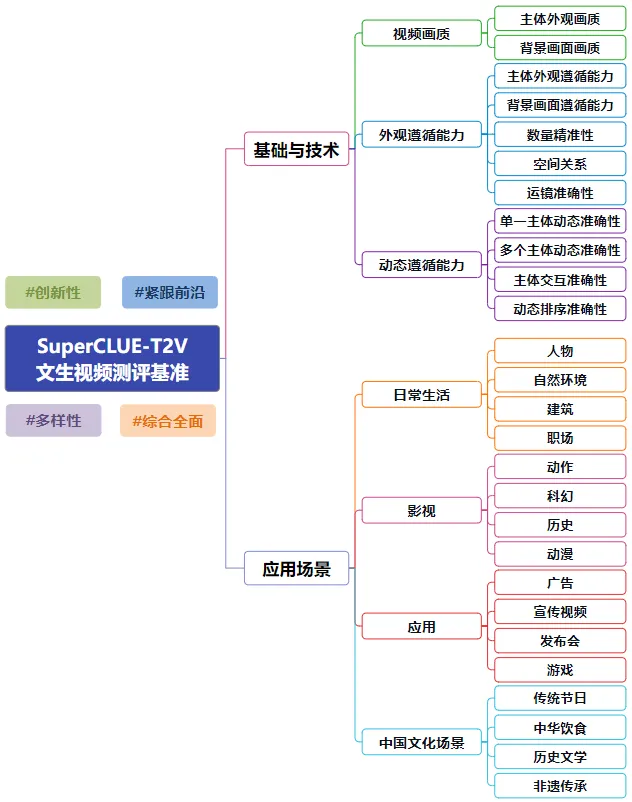
图来源于SuperCLUE官网
比如我们做电商的,我们往往需要“商品展示视频中的商品不要变形”,所以会更看重“外观遵循”这项能力。由此,通过筛选“外观遵循”的分值,我们会发现Luma的分值是最高的。那么我们便可优先测试Luma。
2)自媒体评测
我们也可以通过各种AI自媒体的评测来获知“哪些AI可能更适合我们”。但是并非所有自媒体都要相信,我们要警惕以下账号:
- 天塌党:指天天喊着行业颠覆,XXX行业又要失业的一些自媒体,这些人往往AI都没用过几次,对实际业务也不了解,看到AI厂商的更新公告和测试案例就“高潮”了,上来就劈头盖脸地说大伙要完蛋 以博取流量。
- 广告党:这些号往往会在某家厂商发布某项新功能的适合发视频,其目的就是宣扬别的厂商的新功能。这些号的内容往往会“避重就轻”,给到的案例都是好的案例,对于AI实际存在的问题避而不谈,从而误导用户“这个AI号真牛啊”。
我们选择自媒体的时候,要看看“他们是否有一定的粉丝基础”、“描述方式是否客观”、“是否有足够的案例”,从而判断他们的话是否可信。
3)官方案例
大部分厂商都会放出一定量的官方案例,有的甚至会有官方社区(比如AI视频厂商的创意圈)。

因为这些案例必定是经过精挑细选的,所以我们可从中看到AI厂商能力的“上限”,也能和其他厂商进行快速的横向对比。
4)AI社区:遇事不决,就问群里的大佬。
在群聊里,我们可以问到一些大佬最真实的使用体验,通过这些反馈,我们可以快速获悉“AI在实际应用中的表现”,从而判断AI是否对我们的业务有帮助。
所以在AI时代尽可能地拓展信息源,是一项非常重要的事情。
2. 工具熟悉——熟悉工具才能客观地测试
通过初筛选出的AI工具后,我们需要对这些工具有初步的认知。不然你可能连工具的50%力量都没发挥出来,却由于“自己的不熟悉”而给“一个优质的工具”评判为“不合适”。
那如何快速熟悉工具呢?
在这个时代,我们最不怕的就是学不会工具了。因为现在“教大家用AI赚钱的人”可能比“用AI赚钱的人”还要多,随便上网一搜,全都是“教你怎么用XX AI”的教程。更懒一点的,随便上个知识付费网站,都还能找到手把手教你的。
而且,官方也会“想尽办法教会你”,因为用户用得越好,便能通过优质案例吸引更多用户,带来更多付费。
像是可灵、豆包,他们都提供了“用户教育”相关的功能。
可灵有官方教程功能、创意圈的“一键同款”功能……
豆包则提供了提示词示例功能,用于告知用户“该AI能做什么”。
但无论如何,最重要的是,我们要亲自上手使用工具。弄脏自己双手,亲自体验,不要纸上谈兵。
3. 设计评测指标——设计“描述工具是否适合我们”的量化标准:
由于我们是需要对多个AI厂商进行对比,而我们对比的内容是偏主观的“AI生成内容”,因此我们需要设计一套评测指标,用来描述“工具是否适合我们”。
那么如何设计这套指标呢?以下为个人梳理的步骤~
1)梳理“满足业务需求的标准”。
并非所有人都能立马把一个主观的事物抽象出“客观的评价”的。所以这里有个技巧,我们先问问自己“到底AI生成成什么样,才能视为满足业务需求呢”?
通过这个过程,我们可以去想象 或者找到一些满足业务需求的案例,从中找到一些共性。
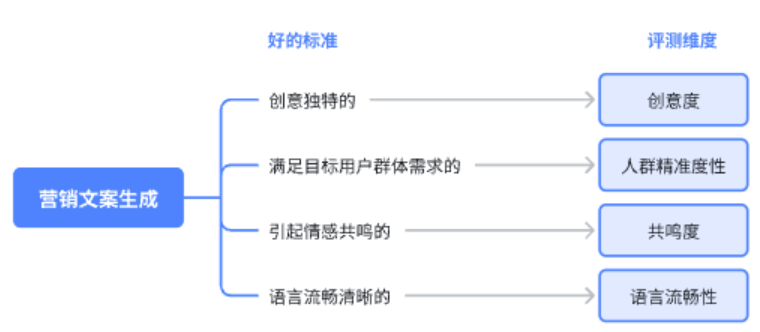
比如在营销文案生成场景,营销文案必须是“创意独特的”、“满足目标用户群体需求的”、“引起情感共鸣的”、“语言流畅清晰的”。
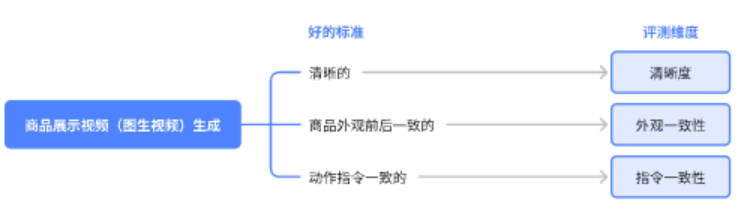
比如在商品展示视频(图生视频)生成场景,生成的成品视频必须是“清晰的”、“商品外观前后一致的”、“动作指令一致的”。
2)从标准倒推“评测维度”。
当我们写好“标准”后,我们倒推“评测维度”就很简单了。只需要使用一个中性词汇对其描述即可。
继续拿上面两个案例举例~
比如在营销文案生成场景~
比如在商品展示视频(图生视频)生成场景~
3)设计每个维度的分值及其分段定义。
最后,我们需要设计每个维度的分值定义。这里定义需要把主观的事情进行“量化”,从而保证最终的分值是客观的,也保证即使进行团队评测,也能够较为公正地进行AI工具评测。
对主观事物进行量化的方法无非是找到其中可被量化定义的事物。
我们可以尝试从中找到可被量化定义的事物,比如一段文章中的“错别字”、“关键词”数量,比如一段文章中有无“XX错误”,这些内容可以通过客观的标准进行描述,从而统计其中的数量。
像是“错别字”、“关键词”这类内容,是能够客观地定义“错别字”、“关键词”,并从中数出这些内容的数量。而像是“美丽画面”的数量这种“主观定义”的事物,则无法用于判断维度分值的定义。
比如错别字数量可以用来衡量“生成正确性”,并得出以下标准。
生成正确性
- 高分(8-10分):少于2个错别字。
- 中等(4-7分):有3-4个错别字。
- 低分(0-3分):大于5个错别字。
比如“画面与指令不符合区域数量”可以用来视频生成AI的“外观指令遵循”,并得出以下标准。
外观指令遵循
- 高分(8-10分):少于或等于1个画面与指令不符合区域数。
- 中等(4-7分):少于或等于4个画面与指令不符合区域数。
- 低分(0-3分):4个以上个画面与指令不符合区域数。
比如AI是否准确分类,这种维度其中只有“准”与“不准”的说法。
分类正确性
- 高分(10分):准确分类。
- 低分(0分):分类不准确。
当然,以上步骤完全可以借力,比如:
1)AI代劳:
AI在这些方面还是挺在行的,写的清晰又全面,我们可以直接描述下业务,把这个问题甩给AI。
我是一个电商行业的从业者,我想测试deepseek在广告文案生成上的效果,现在需要几个评价维度,帮助我用分数来衡量deepseek在这里的表现。
请你写出至少5个评价维度~并给出这5个维度里面,低分、中等、高分的量化定义。
注意,定义需要可量化!

2)抄第三方评测机构标准:
直接基于评测机构的维度进行二次优化和修改,修改的内容可以结合业务的实际需求进行调整。
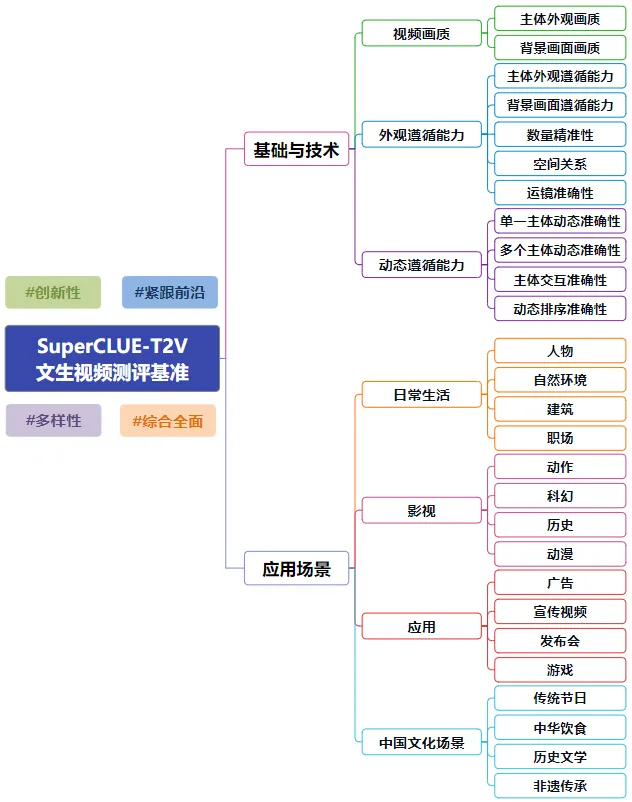
图来源于SuperCLUE官网
比如视频生成场景,我们可以先参考SuperCLUE的指标,列出“主体外观画质”、“背景画面画质”、“主体外观遵循能力”、“背景画面遵循能力”、“数量精准性”、“空间关系”、“运镜准确性”、“单一主体动态准确性”、“多个主体动态准确性”……
然后假设我们是电商业务的“商品展示”场景,那边便可拎出“主体外观画质”、“主体外观遵循能力”、“运镜准确性”、“单一主体动态准确性”这几个维度作为我们的测试重点。
4. 选取测试样本——选择充分且合适的样本;
基于评测指标,使用具有代表性的测试素材在不同方案上进行测试。这些素材需要具备以下特征:
1)样本量充分:
我们的样本不能只有仅仅一两个,需要达到一定的量级,使得AI的能力能被充分测试。
2)贴合评测指标:
所选的样本需要能够对评测指标进行检验,比如测试AI编程水平的时候,要检测其BUG识别能力的时候,至少需要样本中“有BUG”。
3)对不同难度的样本进行分类:
多个样本其实也会有难度之别,所以我们需要对题库进行难度分类,避免题目过难,评测结果分值偏低,最终看不出AI的作用。
对题库进行难度分类的方式和“评测指标设计”中的“分值设置”思路类似,是找到其中的可量化点,然后对其进行难度划分。
比如评测文本AI的“错字识别”能力时,可以直接按样本中的错字数量进行难度划分。
错字识别
- 高难度:大于5个错字。
- 中难度:3~4个错字。
- 低难度:1~2个错字。
5. 执行并记录评分
最后,就是将样本在AI工具上批量测试,并记录相关结论和截图。由于这一部分评价偏主观,最好由同一批人进行评价。
如果样本中存在不同难度,则最好分批次进行测试,分别记录不同难度下的分值,以更精细地判断AI的能力边界。
小结
至此,个人对于AI评测的经验便汇总完了,核心是结合业务需求,设计可被量化的“测试指标”,并设计可分为多个难度的题集。这套方案也是能一定程度上辅助我们量化判断“AI能力对我们业务的作用”,帮助我们在日新月异的AI浪潮下,快速在业务中引入AI的关键一步。
本文由人人都是产品经理作者【柠檬饼干净又卫生】,微信公众号:【柠檬饼干净又卫生】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于CC0协议












