


































OpenAI 下一代模型遭遇重大瓶颈,前首席科学家透露新技术路线
扩展定律(scaling laws)在崩溃前夕?#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。 爱范儿 | 原文链接 · 查看评论 · 新浪微博


OpenAI 的下一代大语言模型「Orion」可能遭遇了前所未有的瓶颈。
据 The Information 报道,OpenAI 的内部员工称 Orion 模型的性能提升没有达到预期,与从 GPT-3 到 GPT-4 的升级相比,质量提升要「小得多」。
此外,他们还表示 Orion 在处理某些任务时并不比其前身 GPT-4 更可靠。尽管 Orion 在语言技能上更强,但在编程方面可能无法超越 GPT-4。

▲图源:WeeTech
报道指出,训练高质量文本和其他数据的供应正在减少,这使得找到好的训练数据变得更加困难,从而减缓了大语言模型(LLMs)在某些方面的发展。
不仅如此,未来的训练将更加耗费计算资源、财力甚至电力。这意味着开发和运行 Orion 以及后续大语言模型的成本和代价将变得更加昂贵。
OpenAI 的研究员诺姆·布朗(Noam Brown)最近在 TED AI 大会上就表示,更先进的模型可能「在经济上不可行」:
我们真的要花费数千亿美元或数万亿美元训练模型吗? 在某个时候,扩展定律会崩溃。
对此,OpenAI 已经成立了一个由负责预训练的尼克·雷德(Nick Ryder)领导的基础团队,来研究如何应对训练数据的匮乏,以及大模型的扩展定律(scaling laws)将持续到什么时候。

▲Noam Brown
扩展定律(scaling laws)是人工智能领域的一个核心假设:只要有更多数据可供学习,并有更多的计算能力来促进训练过程,大语言模型就能继续以相同的速度提升性能。
简单来说,scaling laws 描述了投入(数据量、计算能力、模型大小)和产出之间的关系,即我们对大语言模型投入更多资源时,其性能提升的程度。
举例来讲,训练大语言模型就像在车间生产汽车。最初车间规模很小,只有几台机器和几个工人。这时,每增加一台机器或一个工人,都能显著提高产量,因为这些新增资源直接转化为生产能力的提升。
随着工厂规模的扩大,每增加一台机器或工人带来的产量提升开始减少。可能是因为管理变得更加复杂,或者工人之间的协调变得更加困难。
当工厂达到一定规模后,再增加机器和工人可能对产量的提升非常有限。这时,工厂可能已经接近土地、电力供应和物流等的极限,增加的投入不再能带来成比例的产出增加。

而 Orion 的困境就在于此。随着模型规模的增加(类似增加机器和工人),在初期和中期,模型的性能提升可能非常明显。但到了后期,即使继续增加模型大小或训练数据量,性能的提升也可能越来越小,这就是所谓的「撞墙」。
一篇近期发表在 arXiv 上的论文也表示,随着对公共人类文本数据需求的增长和现有数据量的有限性,预计到 2026 年至 2032 年之间,大语言模型的发展将耗尽现有的公共人类文本数据资源。
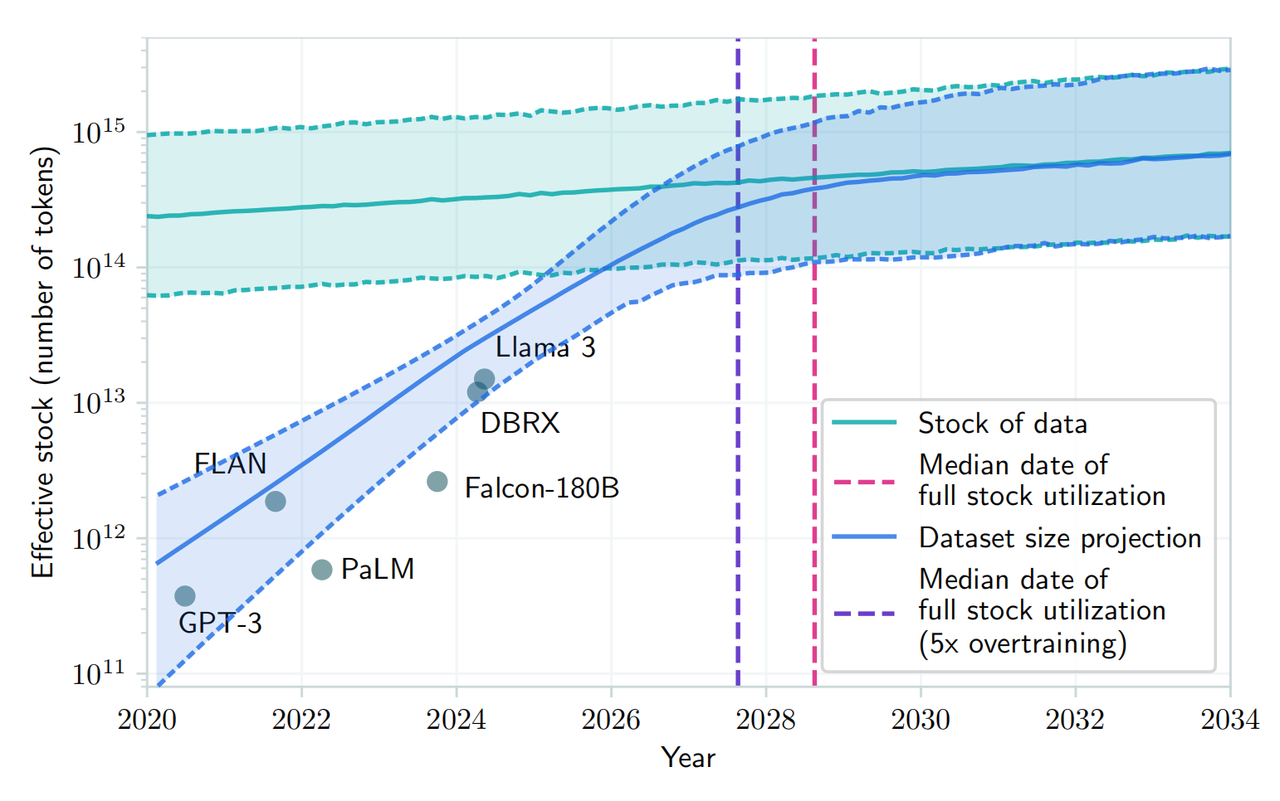
▲图源:arXiv
即使诺姆·布朗指出了未来模型训练的「经济问题」,但他还是对以上观点表示反对。他认为「人工智能的发展不会很快放缓」。
OpenAI 的研究人员也大都同意这种看法。他们认为,尽管模型的扩展定律可能放缓,但依靠优化推理时间和训练后改进,AI 的整体发展不会受到影响。
此外,Meta 的马克·扎克伯格、OpenAI 的山姆·奥特曼和其他 AI 开发商的首席执行官也公开表示,他们尚未达到传统扩展定律的极限,并且仍在开发昂贵的数据中心以提升预训练模型的性能。

▲Sam Altman(图源:Vanity Fair)
OpenAI 的产品副总裁彼得·韦林德(Peter Welinder)也在社媒上表示「人们低估了测试时计算的强大功能」。
测试时计算(TTC)是机器学习中的一个概念,它指的是在模型部署后,对新的输入数据进行推理或预测时所进行的计算。这与模型训练阶段的计算是分开的,训练阶段是指模型学习数据模式和做出预测的阶段。
在传统的机器学习模型中,一旦模型被训练好并部署,它通常不需要额外的计算来对新的数据实例做出预测。然而在某些更复杂的模型中,如某些类型的深度学习模型,可能需要在测试时(即推理时)进行额外的计算。
例如,OpenAI 所开发的「o1」模型就使用了这种推理模式。实际上,整个 AI 产业界正将重心转向在初始训练后再对模型进行提升的模式。

▲Peter Welinder(图源:Dagens industri)
对此,OpenAI 的联合创始人之一伊利亚·苏茨克弗(Ilya Sutskever)最近在接受路透社采访时承认,通过使用大量未标记数据来训练人工智能模型,以使其理解语言模式和结构的预训练阶段,其效果提升已趋于平稳。
伊利亚表示「2010 年代是扩展的时代,现在我们再次回到了探索和发现的时代」,并且指出「扩大正确的规模比以往任何时候都更加重要」。
Orion 预计将在 2025 年推出。OpenAI 将其命名为「Orion」而非「GPT-5」,这也许暗示着一场新的革命。虽然暂时受理论限制而「难产」,我们仍然期待着这个拥有新名字的「新生儿」能给 AI 大模型带来新的转机。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。












